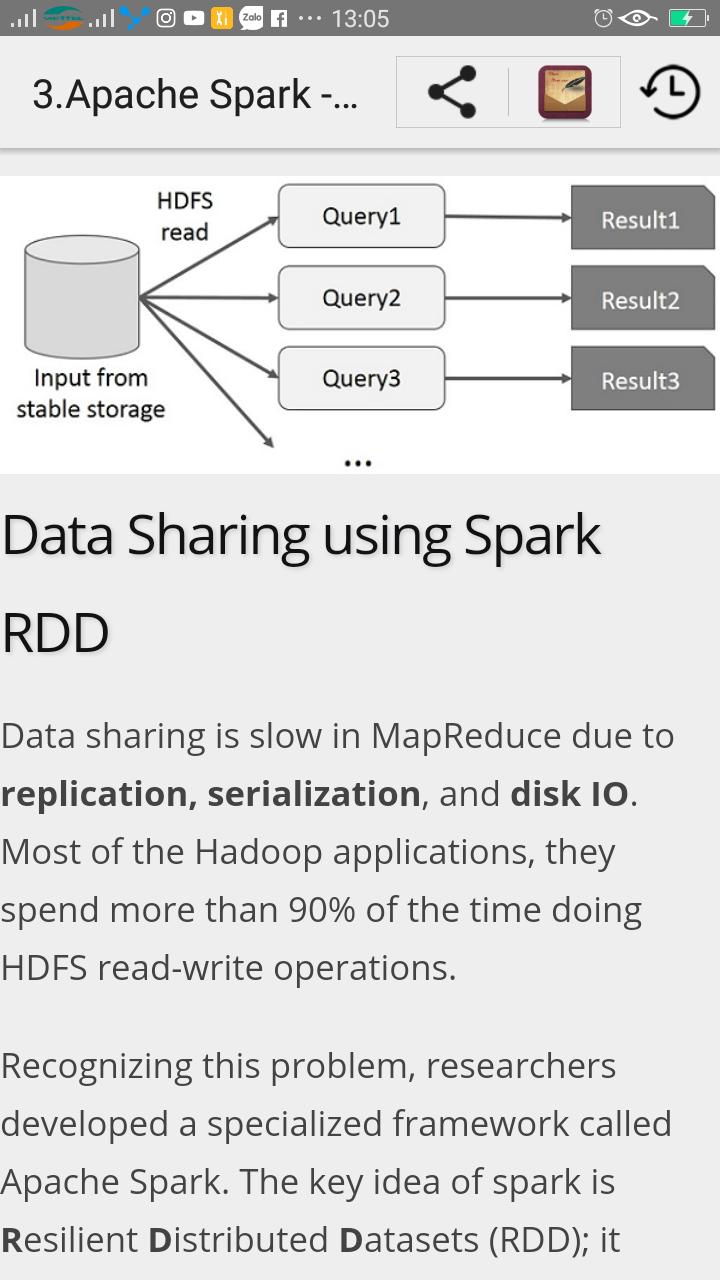
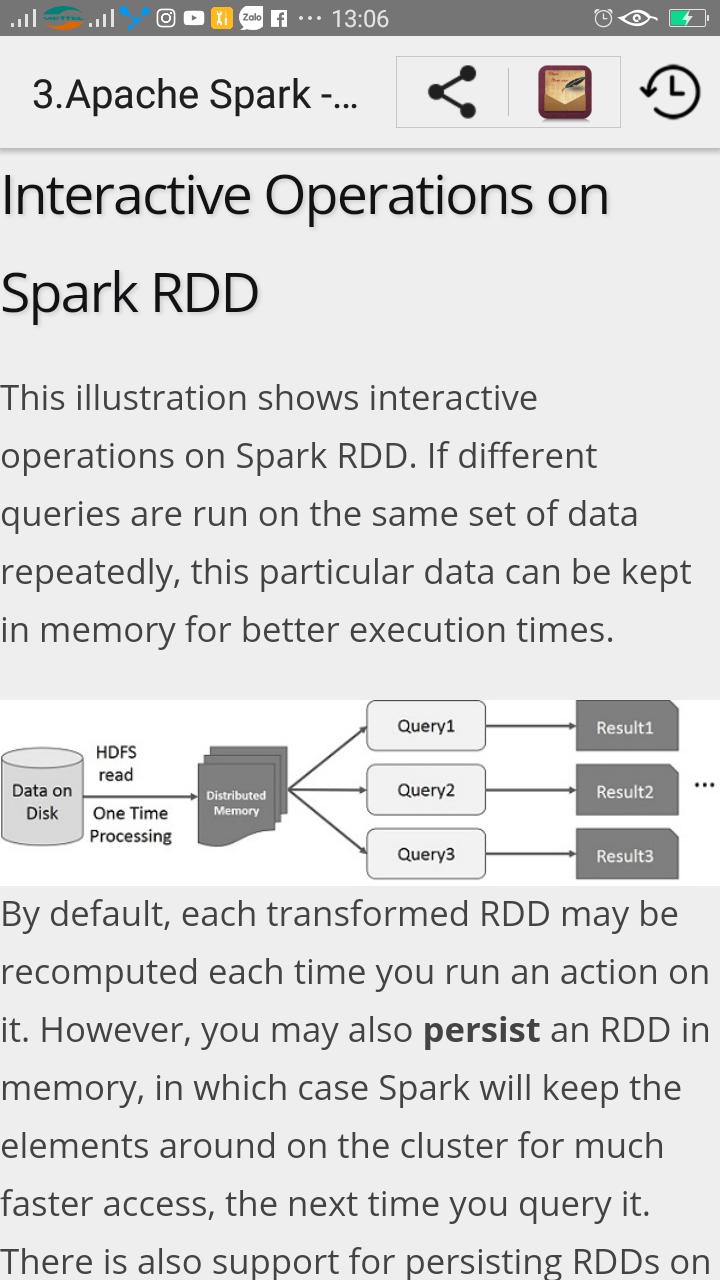
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.
This tutorial has been prepared for professionals aspiring to learn the basics of Big Data Analytics using Spark Framework and become a Spark Developer. In addition, it would be useful for Analytics Professionals and ETL developers as well.
Before you start proceeding with this tutorial, we assume that you have prior exposure to Scala programming, database concepts, and any of the Linux operating system flavors.
Phiên bản mới nhất
1.5Được tải lên bởi
Nong'san Prungtang
Yêu cầu Android
Android 4.0+
Xếp hạng nội dung
Everyone
Báo cáo
Gắn cờ là không phù hợpLast updated on May 17, 2018
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.



APKPure - Kho ứng dụng đa nền tảng chủ yếu tập trung vào Android, cung cấp nội dung phong phú về ứng dụng. Khám phá ứng dụng bạn muốn dễ dàng, nhanh chóng và an toàn hơn, với tính năng tải xuống và cài đặt nhanh chóng và hiệu quả.