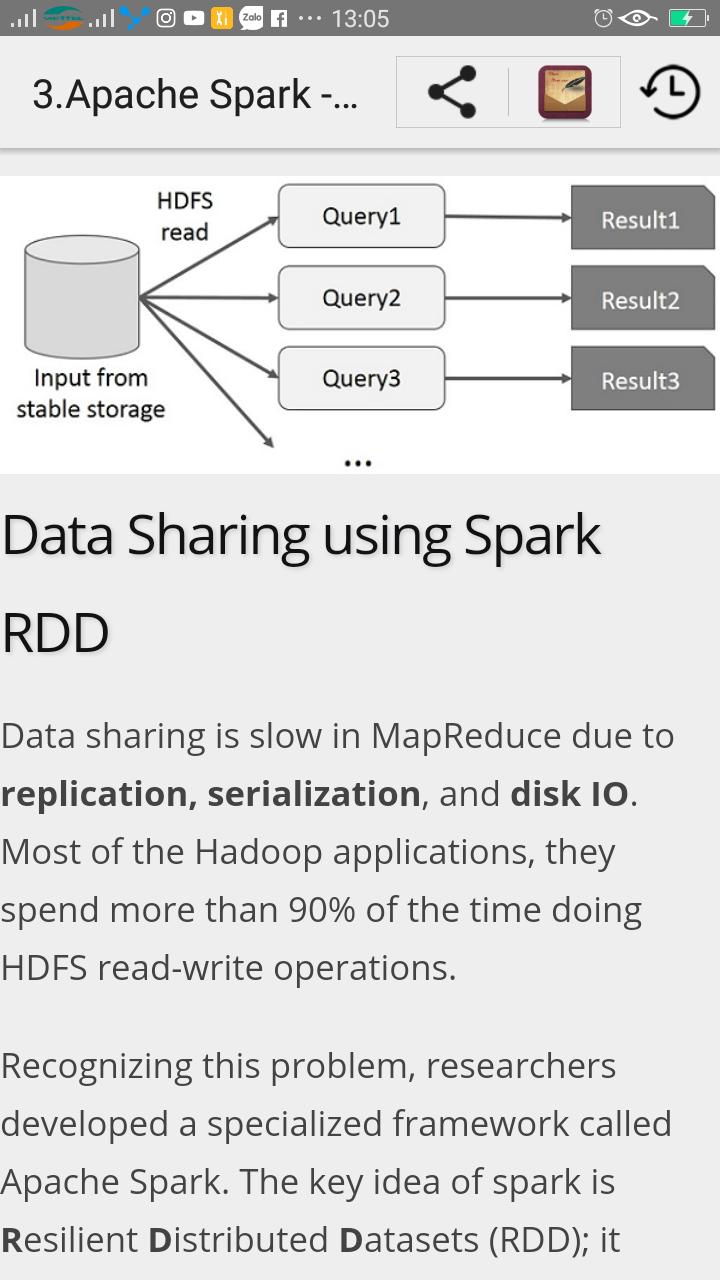
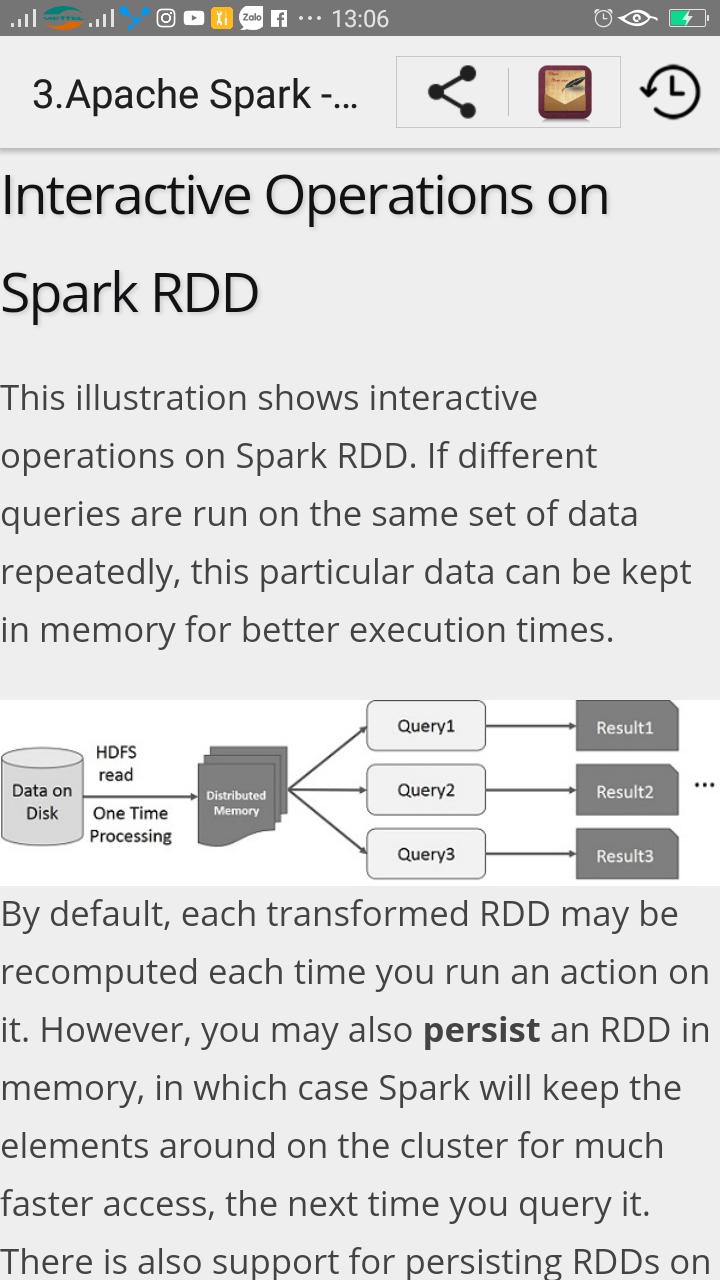
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.
This tutorial has been prepared for professionals aspiring to learn the basics of Big Data Analytics using Spark Framework and become a Spark Developer. In addition, it would be useful for Analytics Professionals and ETL developers as well.
Before you start proceeding with this tutorial, we assume that you have prior exposure to Scala programming, database concepts, and any of the Linux operating system flavors.
Ultima versione
1.5Caricata da
Nong'san Prungtang
È necessario Android
Android 4.0+
Categoria
Gratuita Libri e consultazione APPClassificazione dei contenuti
Everyone
Segnala
Segna come inappropriataLast updated on May 17, 2018
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.



APKPure - Un app store multi-piattaforma principalmente incentrato su Android, che fornisce un'ampia gamma di contenuti relativi alle app. Scopri l'app che desideri in modo più facile, veloce e sicuro, con download e installazioni rapidi ed efficienti.